
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 태그된 유니온
- 이분 검색
- CORS
- 호이스팅
- Promise
- 결정 알고리즘
- async/await
- CI/CD
- TS
- 타입 좁히기
- app router
- dfs
- 인터섹션
- ESlint
- 리터럴 타입
- tailwind
- recoil
- 공변성
- 무한 스크롤
- autosize
- Jest
- 반공변성
- 투포인터
- RTK Query
- useAppDispatch
- map
- webpack
- React
- Cypress
- SSR
- Today
- Total
짧은코딩
병행프로세스와 비동기 프로세스 본문
- 병행프로세스(Concurrent Process)
-병행실행(Concurrent execution on single-core system)

병행성 single core cpu, 1개의 cpu한테 여러 개의 task(프로세스)를 어떻게 시키느냐, 즉 4개의 task가 있을 때 각각의 task를 어떤 식으로 실행하는 게 좋을까?
만약 레디큐에 4개가 줄 서있다. 그러면 운영체제에서 동시에 잘 수행해야 한다. t1의 일부를 실행하다가 내쫓고 t2 일부 실행하다가 내쫓고... 이런 식으로 공용으로 쓸 수 있도록 분할하는 방식이 병행실행이다. 엄밀히 따지면 운영체제 입장에선 동시 실행은 아니다. 하지만 사용자 입장에선 동시 실행처럼 보인다 ->체감 성능을 어떻게 올리는지가 핵심
-병렬실행(Parallelism on a multi-core system)

병렬성: multi-core cpu, cpu가 여러 개인 경우, core1은 t1, core2는 t2 교차적으로 나누어서 동시 실행할 수 있다. core가 몇 개 있느냐에 따라 병렬성이 실행된다.
그래픽카트는 GPU 게임, 비트코인 체굴 등 단위 시간당 많은 처리가 필요한 작업에 사용된다. cpu가 감당하기 어려워서 GPU가 감당하고 있다. 일반적으로 20개 이상의 cpu를 갖기 힘들다. 하지만 GPU는 대량의 약 8704개도 있다.
-Concurrent Process

병행프로그래밍을 할 때 고려해야 할 사항
1. 공유 자원 문제, 병행프로세스는 실행 중인 2개 이상의 프로세스(단 1개의 cpu에서) p1 p2를 각각의 cpu에서 동시에 실행한다 치자, 예를 들어 p1이 memory의 buffer에 데이터를 쓰고 p2는 memory buffer에서 가져다가 써야 한다. 그러면 p1이 먼저 써줄 때까지 p2는 기다려야 한다. 이러한 경우 동시가 쉽지 않다.
2. 상호 통신 문제, p1, p2가 서로 커뮤니케이션할 때, p1이 aaa를 버퍼에 쓰고 p2에 가져가라고 알려주는 경우가 커뮤니케이션, p2입장에서 계속 체크하면 메모리를 사용한다. 그래서 p1이 준비가 되었다고 알려주고 p2는 가져온 다음에 다음 거 넣어달라고 알려줌=>IPC(inter-process commucation)
3. 동기화 문제, 많은 프로세스가 독립적으로 있을 때 각각 순서가 있다. 1번과 2번은 연관 관계가 없으면 동시 실행 가능 하지만 4번 입장에선 1,2,3, 이 모두 완료되어야 실행 가능, 그러면 1 2 3번의 흐름에 4번이 맞춰야 한다.
-Precedence Graph(선행 그래프)

운영체제에서는 병행성이 있는지 없는지를 따지는 방법이 선행 그래프이다.
명령이 4개가 있다.
동시 실행 가능한 것이 1, 2번은 동시 실행이 가능하다 겹쳐지는 게 없기 때문이다.
3번은 1, 2번이 실행되어야 실행이 가능하다
4번은 3번이 실행되어야 실행 가능하다
-선행조건(Precedence Constraint)

7개의 s가 있고 병행성이 있는 건 (s2, s4, s5, s6)와 s3, s5와 s6

순환 선행 그래프는 사이클이 존재한다. 사이클이 존재하면 앞뒤가 안 맞게 된다.
모순이 발생 =>병행성을 따질 수가 없다. 선행 그래프가 아니다
s3는 s2가 끝난 후에만 수행될 수 있고, s2는 s3가 끝난 후에만 수행될 수 있어서 모순이 발생한다.
-Concurrent Statement in program
1. fork

하나의 프로세스가 fork를 만나면 2개의 프로세스로 분리된다.
수도코드
1. s1을 먼저 실행한다.
2. 그리고 fork를 하고 L이라는 라벨을 썼다. fork는 리턴을 2번 한다.
3. 첫 번째 리턴을 할 때 바로 다음으로 리턴되어 s2를 실행한다.
4. 두 번째 리턴은 L이라는 라벨로 가서 s3를 실행한다.
5. 컨트롤이 2개가 만들어지고 s2, s3가 동시에 실행된다.(거꾸로 그림 주고 프로그래밍할 줄 알아야 함)
2. join

2의 프로세스 컨트롤을 합쳐서 join 된다고 한다.
수도 코드
1. 컨트롤이 2개라 count에 2를 준다.
2. fork를 해서 하나의 프로세스를 만든다.
3. 하나는 s1을 실행시키게 하고 2번째 fork는 L1이라는 라벨을 줘서 s2를 실행시키게 한다. (s1과 s2의 순서를 바꿔도 상관없다) s1과 s2가 병행 실행이 된다.
4. join에서 컨트롤을 합쳐야 한다. 따라서 s1입장에서는 s1 실행하고 go to L2로 보내준다.(만약 go to L2를 안 썼으면 s1 실행하고 s2가 또 실행된다)
5. s2입장에서도 실행이 끝나면 L2로 넘어간다.
6. s1이나 s2 중 빨리 끝나는 게 L2를 실행할 수 있다.
7. join count는 count를 감소시키고 count가 0이 아니면 컨트롤을 quit한다.(컨트롤을 없애서 1개로 만든다 => 따라서 먼저 끝난 것은 컨트롤이 없어진다)
8. 2번째 L2을 실행하는 건 count 값이 1이고 -1 하면 0이라 컨트롤 quit가 실행되지 않는다.
9. 따라서 s3가 실행된다.
join 할 프로세스가 4개이면 count 값이 4가 된다.
-fork, join의 실제 예


수도코드
1. fork를 이용해 a를 수행하고 go to L2
2. 그다음 fork를 이용해 컨트롤 리턴되면 L1로 넘어가서 b를 실행하고 L2로 넘어간다.
3. join count를 이용해 컨트롤을 제어한다.
-fork, join 예

single-core cup를 가지고 Concurrent Process를 어떻게 만들까 고민하는 과정이다.
- 병렬프로세스(Prarallel Process)
2개 이상의 프로세스를 물리적으로 동시 실행, ex) 4개의 cpu에서 따로따로 동시에 실행되는 게 병렬

data 병렬성: 처리하고 싶은 데이터가 있고 4개 cpu가 있으면 1/4씩 나눠서 각각의 core에게 던져주는 것
task 병렬성: 일거리를 던진다. 프로세스를 스레드로 나누고 독립적인 코드를 각각의 core에 일거리를 던져주는 것
고려사항
병렬 프로그램의 근본적인 목적은 성능 향상이다.
1. 처리할 task를 어떻게 분리할 것인가(코드의 실행 내용을 따져보고 병렬 수행이 가능한지)
2. 처리량의 균형(data 병렬성처럼 한 곳에 치중되지 않고 어떻게 적절하게 나누는가)
3. 데이터 간의 독립성(아무리 균형 있게 분리를 해도 a와 b라는 부분을 나눴는데 독립성이 없다 그러면 테스트와 디버깅의 어려움이 있다)
-병렬 프로그래밍 사례와 원리
1. openMP(Open Multi-Processing, 오픈MP)
고성능 처리를 일반 프로그래머도 쉽게 할 수 있도록 c/c++ 프로그래밍을 만들 때 병렬 프로그램을 할 수 있도록 할 수 있다 => 일종의 API=라이브러리(함수들의 모음)
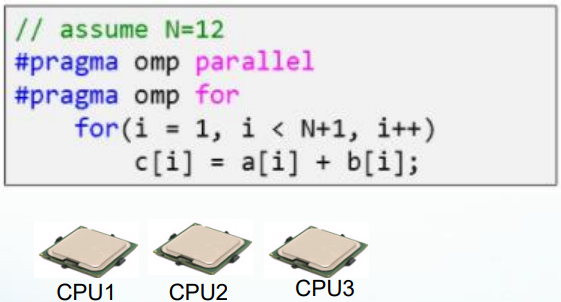

ex) cpu가 3개 있고 사진 같은 프로그램이 있다. cpu가 1개일 때 n이 12면 1개의 cpu가 12번 반복해서 실행해야 한다.
하지만 cpu가 3개이면 4개 단위로 잘라서 스레드 형태로 만들고 3개의 스레드를 각각의 cpu에 던져주면 된다. 각각 4번씩만 반복하면 된다 => 빨라진다
병렬프로그래밍 = 멀티코어 프로그래밍이라고 불리고 대부분의 운영체제에서 지원한다.
2. CUDA(Compute Unified Device Architecture)
하드웨어이면서 소프트웨어의 구조를 제공하고 있다

RTX 그래픽 카드에는 GPU가 8704개가 있다.
GPU전송 shared memory가 있다. 케쉬, 레지스터에는 코드가 저장될 수 있다.
ai(딥러닝): 수많은 데이터를 처리해서 스스로 알아가도록 하는 것 ex) 개와 고양이를 어떻게 구분시키는가? 옛날엔 알고리즘으로 처리하려고 했다 => 오판단할 경우가 많다
하지만 딥러닝은 수백, 천만 장의 고양이 강아지 사진을 보여주고 스스로 알게끔 한다 => 동시 고성능이 필요해서 GPU를 이용한다.
블록체인: 체굴을 하는 건 암호를 풀고 해석해주는 것이다. 수학적 계산을 해야 한다. 많은 gpu가 필요하다
범용적으로 gpu를 사용할 수 있도록 api를 제공해준다.

사진 배열의 사이즈가 8000이고 gpu가 8000 이상이면 한 번에 계산을 할 수 있다.
-Critical Section(=임계영역=임계구역)

병행 프로세스
입력 프로세스, 출력 프로세스가 있다. 키보드 입력 장치로부터 입력받아서 메모리 버퍼에 저장을 하는 게 입력 프로세스, 병행되는 출력 프로세스는 메모리 버퍼에 있는 데이터를 꺼내서 출력한다 => 독립적으로 돌아간다. 단 메모리 버퍼를 공유한다.
-문제점
1. 키보드에서 abc를 입력하면 출력 프로세스는 모니터에 출력한다. 하지만 출력 프로세스가 늦어서 abc를 늦게 가져가면 입력 프로세스는 이를 모른다. 그다음 cdf가 입력되면 abc는 사라지는 문제가 생긴다.
2. 입력 프로세스에서 생길 수 있다. 입력 프로세스가 저장을 한다. 출력 프로세스가 가져갔다는 사실을 알아야 하는데 그걸 안 알려주기 때문에 입력 프로세스에서 문제가 생길 수 있다.
=>성능을 높이려고 사용하는데 공유 메모리를 공유하다 보니까 문제가 생길 수 있다. 입력, 출력 프로세스 부분의 코드에 문제가 생긴다 해서 임계영역이라고 부른다.
프로세스1 a에 9를 저장하면 프로세스2에선 c를 할 수 있다. 만약에 프로세스 1에서 a를 만들기 전에 프로세스 2가 수행되면 결과가 잘못될 수 있다. 공유 메모리를 쓰기 때문에 생기는 문제이다. 이 코드도 임계영역이라고 한다.
=>운영체제 입장에서 임계영역을 가만뒀다가는 오작동이 발생할 수 있어서 통제할 필요가 있다.
-Mutual Exclusion(상호배제)

임계 영역 문제 해결방법 중 하나인 상호배제
A, B의 2개 프로세스가 있다, 선은 시간의 흐름이다.
A가 먼저 t1 시점에 임계영역에 진입을 한다. 실행하던 와중에 t2시점에 프로세스 B도 들어가야 하는 시점이 되었다. 하지만 임계영역에 A가 먼저 있다. B를 임계영역에 들어가게 하면 문제가 생길 수 있어서 blocked 해서 A가 나올 때까지 기다리게 한다.
그 와중에 A는 열심히 프로그램 실행을 한다. 그리고 실행할 코드가 없으면 빠져나오고 B가 들어가서 자기 코드를 실행한다 => 어느 한순간에 하나의 프로세스만 임계 영역에 들어갈 수 있다. 즉 하나가 임계 영역에 들어갔으면 나머지는 못 들어오게 배제해야 한다.
만약에 한 프로세스가 임계영역에서 떠나지 않으면 나머지 코드가 못 들어온다. 그래서 임계영역에서는 빠른 처리를 하여 block 시간을 최소화해야 한다.
Critical Section 부분 사진의 프로세스1을 보면 전체를 임계영역으로 하는 거보다 a=x+y 부분만 임계영역으로 하는 것이 중요하다.
만약 임계영역에서 무한루프가 돌면 다른 프로세스는 죽는다 그래서 운영체제가 이를 막아야 한다.
-상호배제 구현방법

빨간색 부분이 임계영역이면 앞에 진입영역 뒤에 출구영역을 만든다. 그리고 임계 영역과 관련이 없는 잔류 영역을 만든다. 그래서 앞에 4가지 섹션으로 구분한다.
하나가 들어오면 차단시키는 곳이 진입영역 -> 상호배제 사전처리
프로그램이 끝나면 풀어주는 영역이 출구영역 -> 상호배제 사후처리
오른쪽 수도코드
임계 영역 있으면 앞이 진입 뒤가 출구 그 밑이 잔류 영역이다
프로세스1: a=x+y가 임계 영역
프로세스2: c=a-b가 임계영역
-Producer/Consumer Process

병행프로세스 패턴을 갖는 예시
1. 문서 프린트를 한다 하면 만드는 프로세스와 인쇄하는 프린터가 있다
가운데에 공유 버퍼, spooling 할 때 공유하는 자원이 있고 양쪽에서 생산자, 소비자 형태의 구조가 있다.
2. C언어에서 프로그램 짠 걸 실행하려면 컴파일해야 한다. 컴파일러 프로그램이 어셈블리 코드를 만들게 된다. 그러면 어셈블러(프로세스)가 어셈블리 코드를 가져간다. 그리고 기계어로 만든다. 모든 프로그램이 실행되려면 반드시 메모리에 있어야 한다. 그래서 기계어로 된 실행 프로그램을 메모리로 올려주는 적재기 프로그램을 통해 메모리에 올라간다. 그 후에 실행된다.
-> 컴파일러는 데이터를 만드는 생산자, 어셈블러는 소비자
그리고 어셈블러가 생산자가 되어 기계어를 만들면 적재기가 소비자가 된다.
대부분의 모델은 producer consumer가 있고 데이터를 생산해서 가운데에 데이터를 쌓아두고 쌓아둔 데이터를 가져가서 처리, 계산, 출력 등의 역할을 한다 => 협력 프로세스
-병행처리과정에서의 생산자/소비자 문제

버퍼가 있고 크기가 6이고 생산자 소비자 프로세스가 동시에 실행
Step 1: 시작점과 끝 위치 표시하는 out in이 있다
Step 2: 생산자가 a를 생성하면 in이 가리키는 곳에다가 집어넣는다. 그리고 in을 다음으로 옮긴다.
Step 3: 생산자가 b를 생성하고 in위치에 넣고 in을 증가시킨다.
Step 4, 5: 마찬가지로 c d를 넣는다
Step 6: 소비자 타임, 5에서 소비자가 out이 가르치는 위치 값을 꺼내오고 out을 증가시킨다.
문제점
1. 생산자가 5 위치에서 계속 데이터를 만들다 보면 버퍼가 꽉 찰 수도 있다. 그러면 오버플로우가 발생해 데이터가 사라진다.
2. 소비자 프로세스는 계속 가져가서 소비를 한다. 근데 어느 순간 비어 있는 버퍼가 생길 수 있고 비어있는 상태에서 계속 가져가면 쓰레기 데이터도 가져간다. 그러면 오작동이 될 수 있다.
-유한버퍼를 이용한 병행프로세스 처리

공유자원을 사용하기 때문에 문제가 생긴다.
사진
유한 버퍼가 있다.
생산자 프로세스와 소비자 프로세스가 있고 parbegin과 parend로 돌린다.
하지만 병행해서 돌다 보니까 문제가 발생
3가지 조건
1) Empty case, 비어있는 경우: in == out
in과 out 위치 값이 같으면 비어있는 상태다
2) Full case, 가득 차 있는 경우: ((in + 1) % n) == out
n=6, in 위치가 5라 하면, 0 값과 out값이 같으면 꽉 차 있다
3) Other case, 이외의 경우: in > out
데이터가 적절하게 들어있는 경우 in이 out보다 클 때, 뭔가 꺼낼 수 있는 데이터가 들어있을 때
->위 3가지를 가지고 생산자 소비자를 만들 수 있다.
수도코드
-생산자
생산하고
while문 꽉 차 있을 때 넣으면 안 되기 때문에 full case의 조건을 확인해준다, 만약 꽉 차있으면 아무것도 하지 말고 기다려라
생산한 데이터를 버퍼에 넣는다
in을 늘린다 이때 재활용할 수 있도록 mod n을 한다.
-소비자
while 비어있는지 확인을 하고 꺼내간다, 비어있으면 기다리라 한다.
데이터를 꺼내간다
out을 늘려주고 재활용할 수 있도록 mod n한다
=> 이렇게 병행적으로 실행하여 버퍼 1개로 운영 가능하다.
임계 영역을 크리티컬섹션, 엔트리섹션으로 상호배제 시킴으로 인해서 2개가 돌고 있는 프로세스가 문제없이 수행되게 한다.
하지만 이 방식도 문제가 있다. 유한 버퍼이다 보니 비어있는 부분을 이용할 수 없다.
-위 방식의 보완

full과 empty를 체크할 때 counter로 체크
count는 버퍼에 있는 데이터의 개수
count=0 이면 빈 거고 6이면 꽉 차 있다
-생산자
while 카운트 값이 n(배열 크기)와 같으면 꽉 차서 아무것도 안 하게 한다.
데이터 넣고 카운터 추가하는 방식
-소비자
while 비어있는 상태에서 빼면 안돼서 counter=0이면 아무것도 못하게 한다.
데이터 빼오고 out 값 조정
뺏으니 count -1
카운터를 이용해서 생산자 소비자를 병행으로 돌린다.
그러면 빈 공간 1개를 이용할 수 있다
하지만 counter라는 변수도 공유하는 변수가 되었다.
밑에 그림 보면
카운터 값이 5라 하자 각자 2개의 프로세스가 돌고 있다
생산자는 카운터 값을 가져온다. 그리고 증가시키면 6이 된다.
소비자도 각자 돌아서 5를 가져오고, 감소하면 4가 된다
값이 서로 달라질 수도 있다
생산자가 아주 찰나의 순간 빠르면 카운트 값 5가 6으로 되고 이어서 생산자도 카운터를 4로 만들고 오버라이트 되어 4로 바뀐다 이러면 문제가 생긴다
=> race condition이라고 한다. 그러다 보면 임계영역 문제가 여전히 생길 수 있다.
'학교 > 운영체제' 카테고리의 다른 글
| IPC(Inter Process Communication)와 사례연구 (0) | 2021.10.07 |
|---|---|
| 상호배제 해결방법, 프로세스 동기화 (0) | 2021.09.30 |
| 프로세스 개념, 관리 (0) | 2021.09.16 |
| 운영체제의 개요(2) (0) | 2021.09.12 |
| 운영체제의 개요 (0) | 2021.09.11 |



