
- 분류 전체보기 (524)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 호이스팅
- recoil
- app router
- RTK Query
- 태그된 유니온
- ESlint
- 결정 알고리즘
- 투포인터
- 인터섹션
- 리터럴 타입
- autosize
- tailwind
- CI/CD
- MSA
- 무한 스크롤
- Promise
- 타입 좁히기
- useAppDispatch
- SSR
- Jest
- React
- 반공변성
- 인증/인가
- webpack
- 공변성
- async/await
- CORS
- dfs
- map
- TS
- Today
- Total
짧은코딩
인덱스 본문
인덱스
인덱스의 필요성
인덱스는 데이터를 빠르게 찾을 수 있는 장치이다.
ex) 인덱스를 활용해 책 안에 찾고자 하는 항목을 빠르게 찾을 수 있다.
B-트리
인덱스는 보통 B-트리 자료구조로 이루어져 있다.

트리 탐색은 노드 -> 브랜치 노드 -> 리프 노드를 거쳐서 내려온다. 찾는 값인 57보다 같어나 클 때까지를 기반으로 탐색하다가 리프 노드에 도착해서 57이 가리키는 데이터 포인트를 통해 값을 반환한다.
인덱스가 효율적인 이유와 대수확장성
인덱스가 효율적인 이유는 균형 잡힌 트리 구조와 트리 깊이의 대수확장성 때문이다.
-대수 확장성
대수확장성은 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 것을 의미한다.
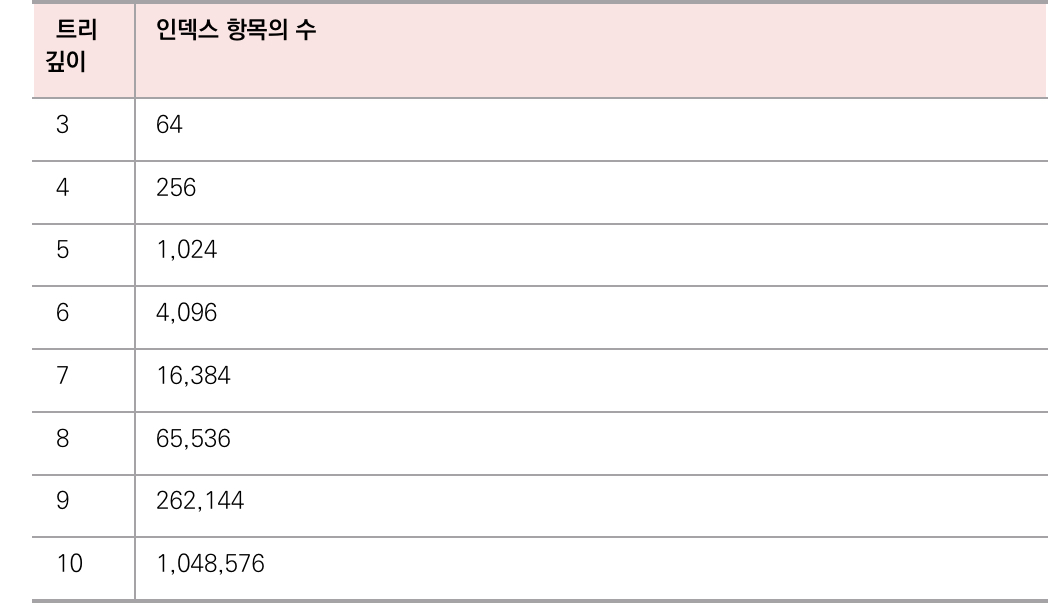
트리의 깊이가 1개씩 증가하면 최대 인덱스 항목의 수는 4배씩 증가한다.
이 말은 트리 깊이 10개 짜리로, 약 100만개의 레코드를 검색할 수 있다. 실제로 인덱스는 이보다 더 효율적이다.
인덱스 최적화 기법
인덱스 최적화 기법은 DB마다 좀 다르지만 기본 골격은 같다. 아래 설명은 MongoDB를 기반으로 설명한다.
1. 인덱스는 비용
인덱스는 2번 탐색하도록 한다. 탐색 순서는 "인덱스 리스트" -> "컬렉션" 이렇게 탐색해서 읽기 비용이 든다.
책의 내용이 바뀌면 목록을 수정하듯이 컬렉션이 수정되면 인덱스도 수정해야한다. 따라서 B-트리의 높이를 균형있게 조절하고 데이터를 효율적으로 조회할 수 있게 하는 과정에서 비용이 든다. 따라서 쿼리에 있는 필드에 무작정 인덱스를 설정하면 안된다. 가져오는 양이 많을수록 인덱스는 성능이 낮아진다.
2. 테스팅
인덱스 최적화 기법은 사용하는 서비스의 객체의 깊이, 테이블 양 등에 따라 달라진다. 그렇기에 항상 테스팅하는 것이 중요하다. explain() 함수를 이용해서 인덱스를 만들고 쿼리를 보낸 이후 테스팅하면서 걸리는 시간을 줄여야한다.
3. 복합 인덱스
여러 필드를 기반으로 조회할 때 복합 인덱스를 생성한다. 복합 인덱스를 생성할 때는 같음, 정렬, 다중 값, 카디널리티 순으로 생성해야 한다. 생성 순서에 따라서 인덱스 성능이 달라지기 때문이다.
1. 같음: "==" 혹은 "equal" 쿼리가 있으면 제일 먼저 인덱스로 생성
2. 정렬: 정렬에 사용되는 필드면 2번째 인덱스로 설정
3. 다중 값: 쿼리가 ">" 혹은 "<" 같은 많은 값을 출력하는 다중 값 출력 필드는 3번째로 설정한다.
4. 카디널리티: 유니크한 값의 정도이며 카디널리티가 높은 순서를 기반으로 인덱스를 설정해야 한다.
ex) 성별의 카디널리티는 남, 여로 2이다. 그에 비해 나이는 여러 카디널리티가 존재하여 나이에 대한 인덱스를 먼저 생성해야 한다.
'CS > 데이터베이스' 카테고리의 다른 글
| 조인과 조인의 원리 (0) | 2023.02.09 |
|---|---|
| 데이터베이스의 종류 (1) | 2022.08.27 |
| 트랜잭션과 무결성 (1) | 2022.08.17 |
| ERD와 정규화 과정 (0) | 2022.08.04 |
| 관계, 키 (0) | 2022.07.19 |



